文章主要介绍的是小扎推出大模型新平台,引领AI生态革命,打造下一个‘安卓’相关内容!
距离OpenAI上次说考虑开源GPT-3,已经过去两个多月了。
结果,GPT-3开源的影子一点儿没瞅着,反倒是一直热衷于开源的Meta又带着他们家的羊驼模型来上大分了,发布了一个进阶版的Llama2。
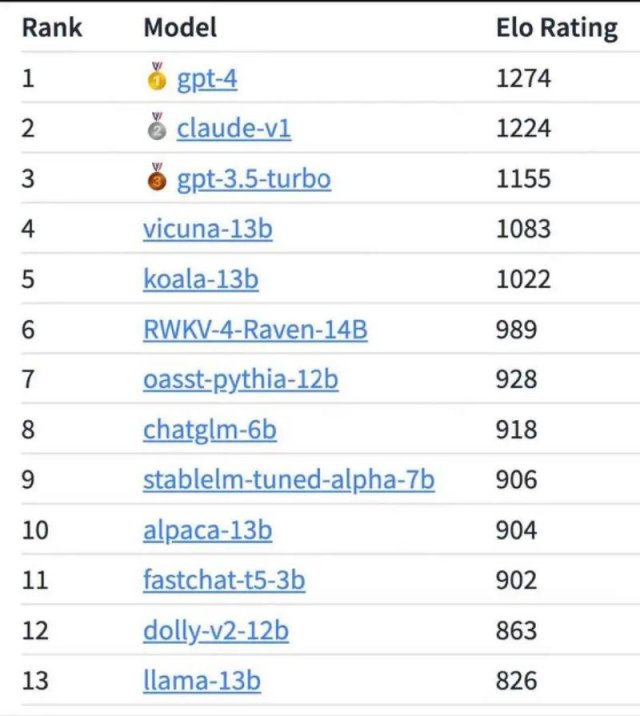
而这次的Llama2,又来了波升级。相比上一代Llama,Llama2增加了40%预训练数据,Token数翻了差不多一倍到2T,模型的参数量也扩展到了700亿。
在长文本的支持能力上,训练文本的窗口也从之前的2048扩展到4096。
而且还发布了一个微调之后的Llama2-Chat模型,专门针对应用场景的优化。
也可以这么理解,升级过后的Llama2初始属性更强了,升级更快了,等级上限也更高了。不过,这些还都只是小菜。
Llama2最大的亮点,就是开源、免费、可商用,而且还支持在高通的芯片上运行。这跟上一代Llama源代码泄露的“被开源”可不太一样,之前即使允许二创,也只是停留在研究领域。
可以免费商用,就相当于拿到了Meta准用许可的“免死金牌”,你拿去干啥都不用担心回头被告侵权。
当然了,这许可也是有点限制的,要是产品的日活超过7亿,那就还得去申请一下。
而在高通的芯片上运行,也一反过去大模型受制于英伟达芯片的常态。

看来,Llama2这次,大有要一举打破OpenAI和英伟达封锁的意思啊。
所以消息一出,很快就在网上引起了一波轰动。
有不明觉厉的吃瓜群众跟风夸赞的,还有人马上用Llama2做了个应用程序出来。
甚至于,Meta的首席AI科学家YannLeCun杨立昆也在推特上为Llama2站台,说它将会“彻底改变大语言模型的行业格局”。

Llama2这次的升级当真就有这么厉害吗?本着求证的态度,差评君联系到了在学术圈和开源社区,都颇具影响力的智源AI研究院,得到的答案是:这次Llama2的升级,其实并不是重点,开源可商用才是。
而与开源的羊驼模型形成对比的GPT,就因为闭源(不开放源代码)而备受吐槽。
当然,关于这开源和闭源的争论,其实从PC时代就已经开始了。当年的开放源码运动里,就诞生出了大家熟知的Linux系统。
因为开源之后,大伙们都能上手魔改代码、移植应用等等,基于Linux的开源生态也扎着根长出了枝叶。而如今的路由器、交换机、智能洗衣机、智能电饭煲、交换机、服务器等等设备上,几乎搭载了各类Linux系统。
包括几年前的美国火星车登录成功,还把Linux带上了火星。
而开源,也逐渐演变成为了一种“开放共享”的精神。
如果没有开源,红帽、ubuntu等桌面操作系统很大概率就不会出现,安卓也不会拿下如今智能手机近三分之二的市场份额。
历史总是惊人的相似,现在开源与闭源的战火很明显已经蔓延到AI领域。有意思的是,一直被诟病不太“Open”的OpenAI,其实在GPT-3之前,一直都是开源的,GPT-2的代码、框架还有论文都开放得很彻底。但到了GPT-3,就只能看论文了。
也难怪马斯克当年执意要退出OpenAI,因为它们完全违背了当初要成立一家开源非营利组织的初衷。但即使顶着外部舆论压力,GPT-3和GPT-4仍然雷打不动的坚持闭源。
至于原因,根据OpenAI官方的说法,是出于“安全”的考虑。
这也合理,作为目前最牛叉的大模型,GPT-4要是真落入了坏人的手里,的确很麻烦。但差评君觉着,还有一个原因是,OpenAI不想放弃现有的技术优势。
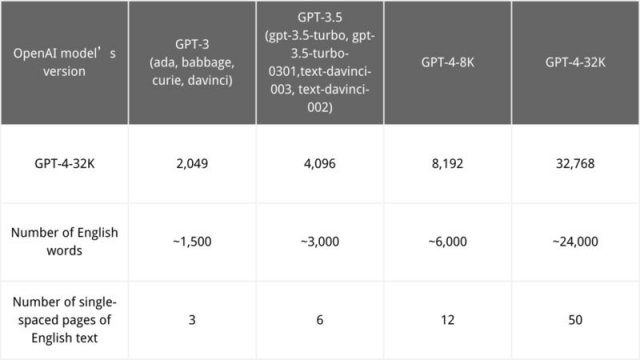
毕竟GPT-4跟前辈们相比,无论是在参数量还是性能上都有了大规模的提升,OpenAI不想让自己的心血白给也可以理解。说白了,闭源更像是一种商业行为。但有一说一,闭源的王座并不会一直牢固。
因为从第一代Llama开始,大模型开源的这把火就已经被点燃了。开源模型的队伍日渐壮大,AMD也宣布要在明年开源OLMo大语言模型。随着更多模型源代码的开放,将会有越来越多的人参与到模型的迭代升级当中,为开源的生态添砖加瓦。而技术壁垒在这个过程中,也会被慢慢拉平。而作为打响了羊驼模型开源第一枪的Meta,也一直在暗戳戳地往里添柴。
当初,为了请AI大拿杨立昆出山,扎克伯格可谓是煞费苦心,不仅答应了他诸多苛刻的要求,而且还立下了研究成果必须开源的规矩。

从2015年把CNN卷积神级网络用到GAN上,提出了DCGAN,到开源基于Python的深度学习框架PyTorch,再到如今全网刷屏的Llama。这么多年了,小扎承诺过的“开放”似乎从来就没变过。
包括Llama之后,Meta又陆续推出了一系列多模态大模型,像什么Imagebind、MusicGen,都是开源的。
而且,对于OpenAI口中,出于安全考虑的闭源理由,杨立昆也是不太认同的。在他看来,使人工智能平台安全、良善、实用的唯一方法就是开源。换句话说,技术掌握在少数人的手里是危险的,只有让监管AI的力量也同时进化,才能尽可能地管住AI。
这在目前看来,暂时只有开源能办到。

而小扎这步棋,又或者说,当年杨立昆坚持开源埋下的种子,或许很快就能看到收获。比如在定制化的大模型上,开源会跑得比闭源更快。

不可否认的是,OpenAI大模型的能力的确很能打,但OpenAI的团队到底能不能根据具体的行业和应用场景去做适配,还需要打个问号。
打个比方,一家服装厂要用GPT-4来优化货物的调度流程,厂里原材料的运送、存储,成品的质量检测,里边儿涉及到太多的行业Know-How,如果不是由企业自家的开发者来操作,OpenAI最终交付出来的效果不一定能满足企业的业务需求。毕竟,咱也不能指望一个搞AI的公司,突然就懂服装了

就算咱抛开质量不谈,算力成本一摊下来,中小企业也很难吃得消。更何况,有些企业的数据涉及商业机密,全都交由OpenAI,老板估计也不放心。
但开源的优势就在于,开发者可以在源代码的基础上,根据业务需求对模型进行微调。
和从头训练大模型相比,在开源的基础上,运用LORA这类低成本的微调方法去构建一个适配下游任务的模型,显然后者的性价比更高。当开源大模型渗透到越来越多的行业以后,开发者反馈的业务需求越多,模型迭代的速度也会越快。
先占领市场,再用量变来催化质变。
当然了,无论是开源,还是闭源,其实都没有绝对的对错之分。OpenAI、谷歌之流坚持闭源也无可厚非。
毕竟几十亿美元砸出来的优势摆在那,在模型层级、Token长度、推理等等能力上,还是领先现在的开源模型不少。
但开源大模型现在势头正猛,抢先一步实现商业化也不无可能。就像不久前Altman说的那样,AI之后会分化,开源负责商业化落地,而闭源则负责研究超级智能。
所以差评君大胆猜测,AI大模型的行业格局,或许会是一两家头部闭源,其他开源模型建立起社区生态的局面。
而在开源推动下的商业化落地,也可能会很快地重塑生活的方方面面,说不定哪天你家的扫地机器人就能帮你遛狗了。差评君还是很期待,在开源的加持下,AI究竟能给我们的生活带来什么样的变化。
文章来源:差评
 相关科技优惠信息推荐
相关科技优惠信息推荐

 科技优惠信息精选
科技优惠信息精选
 领券热度排行
领券热度排行 广而告之
广而告之