大火的Sora,让许多动画、影视行业的人大为恐慌。
为什么Sora做出的是这样的呢?
很显然,Sora混淆了玻璃破碎和液体溢出的顺序,也并不能推理时间和因果关系。
而这也说明,Sora目前还无法理解物理世界!
再比如,Sora团队AdityaRamesh自豪地放出的这个,「蚂蚁巢穴内爬行的POV镜头」,粗看似乎很惊艳,仔细一看,却令人啼笑皆非——
蚂蚁怎么只有四条腿?!
Sora这「人工智障」的表现,也让大家着实松了一口气。
虽说确实生成一些足够惊艳的,但Sora离「扔进一部小说,生成一部电影」,应该还差得远呢。
跑步方向完全相反

椅子未被建模为刚性物体,居然能飘浮
「一只大鸭子走过波士顿的街道」,在第9秒,鸭子把人踩没了
Sora不懂人类的物理世界?AI专家混战
LeCun和马库斯这对「宿敌」,这次却站在了统一战线上,齐喷Sora所谓的「物理引擎」。
LeCun留言表示:嗨,Aditya,蚂蚁有6条腿,不是吗?
马库斯也表示,Sora会造成可怕的后果——
「我们即将有整整一代儿童接受虚假的教育,这些对于天真的观众是完全合理的,然而在生物学上却错误百出。」
今天它弄错的可能是一只蚂蚁,明天就是月球的轨道。诈骗犯会做出许多虚假,普通用户会被蒙蔽,再也不知道什么是真实,什么是虚假。
对于玻璃杯错误摔碎的,马库斯表示这是一个绝妙的例子。
我们需要认识到,并非Sora生成的所有都来自其训练集。Sora也并不总是遵循物理学、生物学和文化的规律。
我最近讨论的77棋盘、4条腿的蚂蚁,和碎裂的杯子一样,都证明了Sora是一个鲁莽的野兽,而非迭代的、基于定律的物理引擎。
OpenAI所引以为傲的对象的一致性,在这些demo中都没有成功。因为模型在训练数据中从未见过,从未被物理引擎产生过。
其实,Sora只是泛化了像素的模式,而并非世界上物体的模式。

对此,英伟达高级研究科学家JimFan表示,我们可以从两个角度来解释这个问题:
(1)可能是因为这个模型根本没有掌握物理知识,它仅仅是在无序地拼凑图像像素;
(2)模型确实尝试构建了一个内部的物理引擎,但这个引擎的表现还不尽人意。就像是第一代虚幻引擎在处理流体动力学和物体变形等问题上,与V5相比有着明显的不足。同样地,V1的渲染效果也远不如V5,并且缺乏物理上的准确性。

至于为什么更倾向于是第二种解释,来自谷歌DeepMind的NandodeFreitas给出了更详细的说明。

生命,以其惊人的复杂结构为例,其实质是在日益增加的宇宙混沌中创造出秩序。类似地,在训练过程中,神经网络通过消耗能量来减少混乱,从而更有效地进行预测和泛化。我们甚至将这种能量损失称为「负熵」。
就像生命一样,网络也是更广阔环境的一部分,这个环境为它提供数据和反馈。同时,这一过程也会为宇宙带来更多的混乱(例如TPU和GPU产生的热量)。
总的来说,我们已经具备了智能(生命的一种衍生属性)的所有要素,包括对物理学的理解。
一个规模有限的神经网络能够预测任何情况发生的唯一方式,是通过学习能够促进这种预测的内部模型,包括对物理定律的直观理解。
基于这种直觉,我找不到任何反对JimFan观点的理由。
随着我们获得更多高质量的数据、电力、反馈(也就是微调和基础化),以及能够高效吸收数据以降低熵的并行神经网络模型,我们很可能会拥有比人类更擅长推理物理的机器,并且希望它们能教会我们新知。
顺带一提,我们也构成了神经网络的环境,通过消耗能量来创造秩序(比如提升神经网络训练数据集的质量)。
关于生命和「熵」:https://newscientist.com/article/2323820-is-life-the-result-of-the-laws-of-entropy/
Sora「世界模型雏形」陷入重重争议
其实,Sora初一面世,OpenAI声称「扩展生成模型是构建物理世界通用模拟器的一条可行之路」的说法,就得到了诸多专家的质疑。前谷歌、Facebook技术主管Hongcheng表示——「模型不大可能通过被动看训练数据,就能掌握物理定律。」
再聪明的智能体,也不大可能通过看太阳东升西落的,就能悟出地球围着太阳转。人类看了几千年苹果掉到地上,也是直到牛顿的时代才发现了引力。
多位业内人士表示,说Sora是数据驱动的物理引擎的说法很愚蠢。它的荒谬性,就好比我们收集了行星运动的数据,输入到模型中,模型预测出行星位置,就说这个模型在内部复现了广义相对论一样。
像Sora这样的DiffusionTransformer,底层是基于机器学习的随机梯度下降加上反向传播。
这就意味着:Sora并没有逻辑推理能力!
本质上,它只是在将训练的数据压缩成模型的权重罢了。只是按照某种规则更新参数,以达到最小误差的配置,并不进行逻辑推理。
梯度下降加上反向传播,往往会找到似乎有效但实际上脆弱的解决方案,因此它很容易崩溃。
就像苍蝇寻找气味源头一样,它总是朝着气味最浓的方向去寻找,就像梯度下降算法根据梯度的方向更新参数,以逐步接近损失函数的最小值。
基于这种模式,是无法学会物理规律的。
而对于Sora「没有在学习物理,只是在二维空间中处理像素」的说法,英伟达高级科学家JimFan表示自己不能苟同。
这种观点,就好像说「GPT-4不学习编码,只是采样字符串」一样。要是这么说的话,我们还可以说「Transformer所做的只是处理一系列整数(tokenID)」,「神经网络所做的只是对浮点数进行处理」。
Sora的软物理模拟,是大规模扩展文本到训练时的一项「涌现特性」。
为了能够生成可执行的Python代码,GPT-4必须掌握特定形式的语法、语义和数据结构。不过,GPT-4并不直接保存Python语法树。
同样地,Sora需要掌握将文字描述转化为3D图像、进行3D转换、光线追踪渲染以及应用物理规律的技巧,从而尽可能准确地对像素建模。它需要像学习游戏引擎开发那样,掌握这些技能。
如果我们暂时不考虑交互性,那么UE5可以被看作是一个复杂的像素生成过程。Sora也是用于生成像素的,但它是基于端到端处理的Transformer技术。它们在概念上是处于同一层面的。
不同之处在于,UE5是通过人工精心设计且精确的,而Sora则完全依靠数据学习得到,更加依赖直观的理解。
谷歌深度学习专家、Keras创始人FrançoisChollet表示,这个话题其实是老生常谈了。
从2016年以来,关于生成模型和神经辐射场是否融入了对物理规律的理解,就有不少讨论。
的确,这些系统具备根据给定物理场景预测未来发展的能力,它们实际上是基于一套物理模型工作的。
问题在于,这套模型的准确度如何?能否应用于未曾训练的新情境中?
这些问题,标着着两个世界的分水岭,这两个世界之间,有着截然不同的可能性。
在一个世界里,生成的图像仅用于媒体制作,看上去似乎真实,实际上却并非真实世界的反映。
而在另一个世界中,这些图像能作为现实世界的模拟,帮我们对未来作出可靠预测,这对科学研究意义重大。
不过,当前模型存在一些基本限制,无法捕捉到物体恒存性这样的视觉现实基本原理,这个概念即使两岁孩童也能理解。
人类研究者是有办法对之改进的。
如果能通过增加模型训练数据的采样密度,在更广泛、更深入的数据上进行训练,就能提高模型性能。
到那一天,我们就能来预测天气、创建风洞模拟器、预测太阳活动了!
但如果我们想将模型应用于游戏引擎和上,是想构建广泛泛化的现实世界模型,就行不通了,模型不是这么用的。
Sora的技术并不新
还有很多大佬表示,Sora的技术其实并不新。
LeCun转发了华人学者谢赛宁的推文,认为Sora基本上是基于谢赛宁等人在去年被ICCV2023收录的提出的框架设计而成的。
而和谢赛宁一起合著这篇的WilliamPeebles之后也加入了OpenAI,领导了开发Sora的技术团队。
时空patch,是Sora创新的核心。
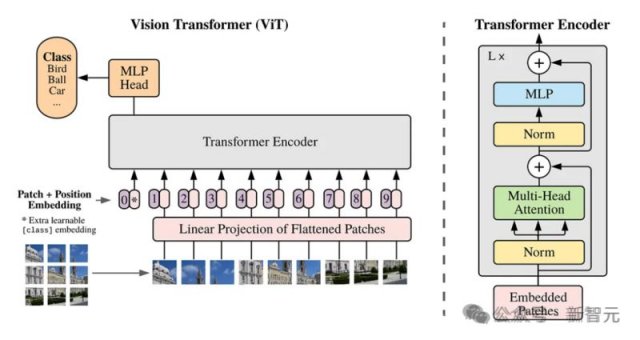
它建立在GoogleDeepMind早期对NaViT和ViT(视觉Transformer)的研究之上。而这项研究,又是基于一篇2021年的「AnImageisWorth16x16Words」。
这其中Sora所做的,就是把Diffusion和Transformer架构结合在一起,创建了diffusiontransformer模型。
马毅教授也表示,Sora与之前不同的地方,就是用Transformer实现了diffusion和denosing。
而这其实就是马毅团队去年在NeurIPSWhite-boxTransformer所预示和证明了的——
假设数据分布是mixedGaussians,那Transformerblocks就是在实现diffusion/扩散和denoising/压缩。
不过,当时团队苦于没有足够的数据和算力,无法在diffusionmodel上验证,只能在MaskedVAE,DINO,BERT,以及GPT-2上做了验证。
而这次Sora的发布更加证明了,在相同条件下,白盒的TransformerCRATE构架在性能上已经能超越传统的Transformer,而且完全可解释和更加可控,因此会提升和文本的生成技术。

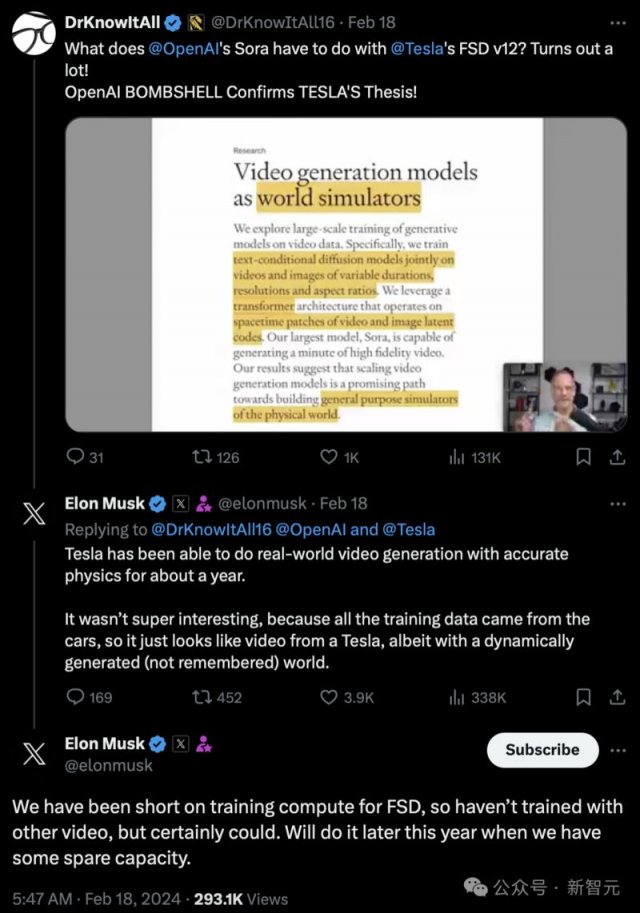
有趣的是,连马斯克也跳出来说,特斯拉早在一年前就掌握了类似OpenAI的生成技术,它的真实世界模拟和生成是是全世界最好的。
并且,特斯拉生成超越OpenAI的地方就在于,他预测了极其精确的物理场景,这对自动驾驶至关重要。
那么,特斯拉怎么让OpenAI抢了先呢?
马斯克表示,自己早就想用特斯拉做游戏了,但不幸的是,他们必须在发布无监督的FSD后才能制作游戏。
动画师:Sora距离替代人类,还早呢
无独有偶,一位动画师也表示,自己完全没有对Sora感到害怕。
他的理由是,因为动画制作需要反复修改,尤其是面对客户的需求时。
面对反复的修改要求,人类动画师是能轻松应对的,而AI则很可能选择重新出一幅作品。
哪位客户会喜欢这种方式呢?
目前AI无法给客户又完整又高质量的作品。
可能很多人觉得,过于关注细节是吹毛求疵,但客户要的就是吹毛求疵。
对于他们珍爱的IP或作品,他们可不希望每次修改都伴随着角色、设计、构图、背景的大改动。
目前Sora还端不了谁的饭碗,除了展现一下AI的潜能外,实际的应用价值并不大。
 相关科技优惠信息推荐
相关科技优惠信息推荐

 科技优惠信息精选
科技优惠信息精选
 领券热度排行
领券热度排行 广而告之
广而告之