本文给大家分享的是英伟达推出大语言模型,专注助力芯片设计创新的相关内容!
英伟达,全球领先的人工智能计算公司,推出了一款大语言模型。这款模型将如何助力芯片设计创新?它将如何改变我们的生活?它将如何推动科技的发展?
这些问题都值得我们深入探讨。让我们一起跟随英伟达的步伐,探索这个充满无限可能的新世界。
英伟达推出了自己最新的430亿参数大语言模型——ChipNeMo。

△英伟达首席科学家Billdally
以英伟达H100TensorcoreGPU为例,它由数百亿个晶体管组成,在显微镜下看起来像一座精心规划建设的城市。
这些晶体管连接在比人类头发细1万倍的地方“街道”上面,需要多个工程团队合作两年多才能完成,其间繁琐而庞大的工作量,可见一斑。

在英伟达看来,随着像ChipNeMo这样的大语言模型的出现,所有的工作流程都会提高效率。
用Billdally的话来说,这项工作标志着将大语言模型应用于半导体设计复杂工作的重要第一步。
它表明,即使在高度专业化的领域,它也可以使用其内部数据来训练有用的生成人工智能模型。
英伟达设计芯片有新的帮手
总的来说,ChipneMo可以帮助英伟达内部的芯片设计师完成三大工作。
首先是问答。
ChipNemo包含一个原型聊天机器人,它可以回答关于GPU架构和设计的问题,并帮助许多工程师在早期测试中快速找到技术文档。
例如,你可以问它:为什么我们需要添加重新计时阶段(retimingstages)?

基于这个问题,ChipNemo会给出准确的答案:重新计时阶段的增加是为了改善设计的时间顺序,并考虑芯片不同部分之间的物理距离。
通过增加重定时间,我们可以减少信号在芯片不同部分之间传输所需的时间,这有助于提高设计的整体性能。
重定时间还可以帮助减少信号上可能发生的噪声和干扰,从而进一步提高设计性能。
二是DEA脚本生成。
例如,您只需要用自然语言向Chipnemo提出生成代码的要求:在TOOL1中编写代码,输出给定矩形(0、0、100、100)中触发器单元的数量。

只需等待一会儿,带有注释的代码片段“啪的一下”就生成了。
据了解,英伟达仍在开发代码生成器(如下图所示),未来将与现有工具集成,使工程师使用更方便。
最后是bug的总结和分析。
芯片设计师只需向ChipneMo描述情况,例如,prompt的内容可能包括bugID、Synopsis、Module和Description等等。

然后ChipneMo会根据prompt给出技术总结和管理总结。
ChipNeMo是怎么炼成的?
在数据集方面,英伟达主要采用bug总结和设计来源(DesignSource)、与维基百科、GitHub等硬件相关的文档、代码和自然语言文本。
经过集中的数据采集过程,最终经过清洗和过滤,形成了241亿个token。
在算法和架构设计方面,英伟达并没有直接部署商业和开源的大语言模型。
但主要采用这些领域的自适应(Domain-Adapted)技术包括自定义标记器、领域自适应持续预训练、领域具体指令监督微调(SFT),以及领域自适应检索模型。
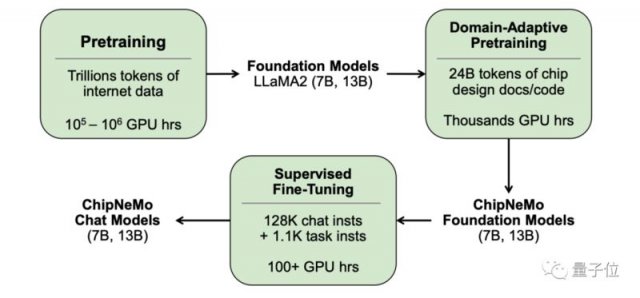
在这种方法下,大语言模型在工程助理聊天机器人、EDA脚本生成、bug摘要和分析三个应用中的性能得到了提高。
结果表明,这些领域的自适应技术使大型语言模型的性能超过了一般的基本模型;同时,模型的大小可以减少5倍,并保持相似或更好的性能。
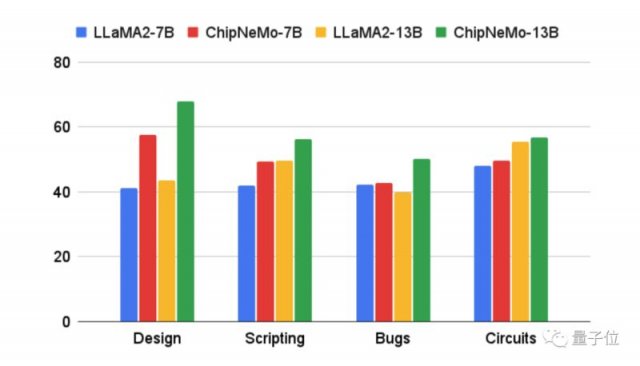
作者也承认,尽管目前的结果取得了一些进展,但与理想的结果之间仍有改进的空间。进一步研究LLM方法将有助于缩小差距。
参考链接:[1]https://blogs.nvidia.com/blog/2023/10/30/llm-semiconductors-chip-nemo/
[2]https://www.eetimes.com/nvidia-trains-llm-on-chip-design/
[3]https:/d1qr31qr3h.cloudfront.net/publications/ChipNeMo(24).pdf
这次,和英伟达推出大语言模型,专注助力芯片设计创新有关内容就为朋友们整理到这里,更多优惠活动资讯信息可查看本站其他栏目。
 相关科技优惠信息推荐
相关科技优惠信息推荐

 科技优惠信息精选
科技优惠信息精选
 领券热度排行
领券热度排行 广而告之
广而告之